
摘 要: 基于.NET平臺,結合SQL Server2005數據庫,設計了一個針對日常卷煙產品質量反饋意見匯總的自動文摘系統。系統的運行可以極大提高煙廠分析人員的工作質量和效益,減少差錯,減輕勞動強度,提高市場測試評價人員的工作效率。因此,面向卷煙質量評價的自動文摘系統,可以作為分析市場測試評價信息的有效工具,在實際中也得到了良好的應用。
關鍵詞: 卷煙質量評價;.NET平臺;自動文摘系統
隨著經濟的飛速發展,企業的競爭也越來越激烈,煙廠的卷煙產品質量的及時反饋與匯總對煙草企業的發展有著重要的作用。目前,卷煙產品的質量評價主要依靠評吸專家經驗通過品嘗來完成,其評價結果受個人的主觀愛好、生理差異和心理狀態等因素的制約,由于評吸人員比較多,描述比較復雜,人為的分析和整理耗時比較長,無法及時地對日常卷煙產品質量反饋意見進行匯總。因此,研究一種快速從消費者對卷煙質量綜合評價數據中挖掘質量優劣信息的方法,是卷煙數字化設計發展的需要。
為了滿足煙廠企業的需求,本文基于.NET平臺,結合SQL Server2005數據庫,基于三層結構的思想,設計了一個針對日常卷煙產品質量反饋意見匯總的自動文摘系統。與傳統的人為分析和整理相比,該系統功能完善、性能穩定、可移植性高,可以極大提高企業市場測試評價人員的工作效率,減少差錯,減輕勞動強度。因此,面向卷煙質量評價的自動文摘系統,可以作為分析市場測試評價信息的有效工具,在實際中也得到了良好的應用。
1 系統結構
1.1 Visual Studio.NET技術
面向卷煙質量評價的自動文摘系統采用.NET技術架構C#設計。現階段.NET平臺主要由以下幾部分組成:Windows.NET、.NET框架、Visual Studio.NET、.NET企業服務器、Web服務和.NET應用以及模塊構建服務[1]。Windows.NET是指Windows操作系統的下一代產品, .NET框架運行于該系統之上,提供對.NET框架應用的運行支持。Visual Studio.NET則是開發.NET框架應用的集成開發環境。在.NET框架的更上一層,是具體的應用和微軟公司為.NET平臺提供的服務,包括Web服務、企業服務器和模塊構建服務等。
.NET Framework的誕生解決了許多開發人員多年來一直困擾的問題,并提供了這些問題的解決方案。每一種編程語言都有自己獨特的地方,如它們可能是強類型的,有垃圾回收機制、基于例外的錯誤處理,或是以虛擬機方式運行,以及擁有強大的類庫[2]。Visual Basic、Powerbuilder以及C++標準模板庫(STL)或是其他語言都有一些這樣的特性。然而,Java語言以及基于Java的J2SE和J2EE框架表現得最為出色,以至于常常有人將Java和微軟的.NET Framework相提并論。現在微軟正在將最好的特性融入自己的產品中,這其中包括支持多種語言的.NET Framework。微軟所做的一切,將在它未來的開發語言和工具中得到體現[1]。

其中,分詞詞表是詞匯量足夠大的一個中文詞典,系統使用參考文獻[4]提供的一個中文分詞詞表[5]。名詞性指標詞詞表用來存儲日常卷煙產品質量反饋意見匯總表中出現的名詞信息,如刺激性、香味、余味、煙氣、口感、雜氣、外觀質量等,這些名詞是重點評價分析卷煙質量的指標項。情感詞詞表用來存儲評吸人員對卷煙產品質量描述的情感評價信息,包含一篇文檔中出現的情感形容詞、詞頻及情感極性。其中,形容詞為主關鍵字,包括較好、適中、較差、較小、較濃等。每個形容詞在對卷煙的名稱指標詞的評價情感下都對應了一個極性。其中,0代表中性,1代表褒義,-1代表貶義。停用詞表里存放著一些虛詞、連詞等無實際意義的詞,以便在進行分詞操作時將文檔中含有的停用詞表中的字、詞去掉,以減少不必要的資源浪費,提高分詞速度。這些基礎信息為提取和生成評價信息的摘要提供了有效的數據。
2.2 系統的功能設計
隨著傳統的面向通用領域的自動文摘技術[6]的日趨成熟,越來越多的目光轉向了針對特定領域的、更加個性化的自動摘要技術,以滿足更加豐富的需求。本文設計了面向卷煙質量評價這一特定領域的自動文摘系統。該系統主要包括5個模塊:文本預處理模塊、文檔分詞模塊、加載詞庫模塊、詞頻統計分析模塊及摘要生成模塊。系統的結構模型如圖2所示。
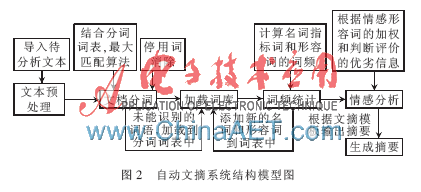
系統各模塊具體的功能如下:
(1)文本預處理模塊:將待分析文本信息按照一定的標準格式導入,即按照計算機能夠識別的形式導入文本信息。為保證文本標識的準確性,在進行文檔處理時,統一使用全角的標點符號。
(2)文檔分詞模塊:此模塊為摘要系統的首頁所顯示的內容,導入的待分析文檔信息將在窗體中顯示出來。首先對待分析的文檔信息進行分詞處理,并把文檔中的停用詞等一些非重要詞剔除,分詞結果中每個詞中間用空格隔開,在分詞結果中提供了未能識別的候選新詞,在加載詞庫模塊中可以把未能識別的候選新詞添加到分詞詞庫中,從而提高文檔分詞的效率。
(3)加載詞庫模塊:由于文檔分詞模塊不可能達到100%的分詞準確率,不可避免地會出現不能識別的新詞,在此模塊中,可以把這些未能識別的新詞加載到分詞詞庫中,可以隨時添加及更新分詞詞庫,從而提高分詞的準確率;在該模塊中,還可以添加評價卷煙質量的名詞指標詞和形容詞性的情感詞。
(4)詞頻統計分析模塊:在該模塊中,根據標點符號將待分析的文檔劃分成一個個的句子,對每個句子進行分詞,根據名詞庫統計待分析文檔中出現的名詞頻率,并把與名詞相關的句子顯示在單獨的列表中,然后統計每個名詞對應的句子中形容詞的詞頻,顯示詞頻統計的相關信息。
(5)摘要生成模塊:通過對文檔的統計分析,系統可以自動計算分析出每個包含名詞指標詞的句子中,各名詞指標詞的情感值的加權和,系統自動組合各名詞指標詞和其對應的情感形容詞,從而得到評價摘要。
3 系統實現與應用
3.1 最大正向匹配算法的C#實現
本系統采用最大正向匹配分詞算法[7],該算法復雜度比較小,技術實現比較容易,分詞效率高,以下是程序中實現正向最大匹配算法的部分關鍵代碼:
int maxlen=8;//最大詞長為8字符(即4個漢字)
string Separator="";//分詞結果以空格隔開
private ISegmentDictionary SegmentDictionary=ne
w ForwardSegmentDictionary();//定義分詞詞典
public void Segment(string text,StringBuilder result)
//對text進行正向最大匹配分詞
{while(!string.IsNullOrEmpty(text))
//文本text不空則循環分詞
{int len=text.Length;//文本的長度
int subLen=maxlen;//從最大詞長開始匹配
string strWord="";
while(len>2)//文本中有詞則循環
{strWord=text.Substring(0,subLen);
subLen=subLen-2;
if(SegmentDictionary.Contains(strWord))//匹配詞典
{result.Append(strWord);
result.Append(Separator);
//把匹配的詞語添加到分詞結果中
break;}}
text.Remove(0,subLen);//把匹配的詞語從文本中除去
return result;}}
3.2 系統實現
本系統采用C/S架構,可以在Windows 2003,Windows XP,Windows 7操作系統平臺上運行,本文在.NET平臺下,采用Visual C#開發語言、Microsoft SQL Server2005后臺數據庫,ADO.NET進行開發的Windows Form應用程序。在日常卷煙產品質量市場測試評價的實際業務中,該系統包含了使用簡單的圖形用戶界面,可以作為分析市場測試評價信息的有效工具。另外,本系統測試過山東中煙工業公司提供的1 000條左右的消費者評價數據信息。下面以部分評價數據信息為例,通過該系統得到摘要信息,系統運行界面圖分別如圖3、圖4、圖5所示。
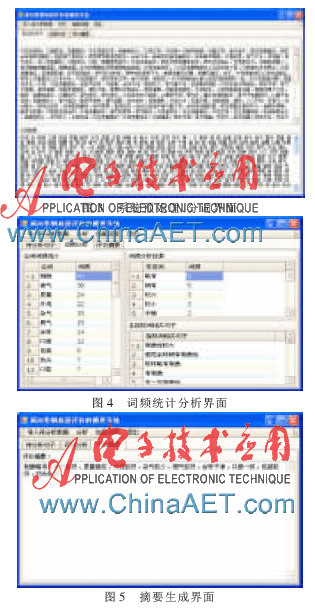
在系統預處理、分詞界面中,可以看到分詞結果以及未能識別的候選新詞,這些候選新詞能夠加載到分詞詞庫中;在詞頻統計分析界面中,向用戶展示各名詞指標詞和形容詞的詞頻,并按照從大到小排列,與名詞指標詞有關的句子也顯示在該界面中,方便用戶分析判斷評價結果;在摘要生成界面中,系統自動分析得到摘要結果。
在系統性能方面,人為的分析消費者對卷煙質量綜合評價數據,消耗大量的時間和精力,系統能夠快速地得到數據的統計分析以及摘要結果,大大地提高了市場測試人員的工作效率。
本文從煙草企業的實際應用出發,面對人為分析和整理卷煙產品質量耗時比較長這一問題,設計了一個針對日常卷煙產品質量反饋意見匯總的自動文摘系統。該系統基于.NET平臺,采用三層架構,結合SQL SERVER 2005數據庫技術,可以很好地實現程序員并行開發,提高程序的開發速度。為了驗證所提出方法的可行性和有效性,本文采用內部評價方法對開發的文摘系統進行評估。從山東中煙工業公司提供的卷煙質量綜合評價數據中獲取文摘,進行評測,可以看出本文提出的面向卷煙質量評價的自動文摘系統,能夠滿足煙廠對日常卷煙產品質量反饋意見及時匯總的需求,與傳統的人為的分析方法相比,極大地提高了煙廠分析人員的工作質量和效益,減少了差錯,減輕了勞動強度。
綜上所述,本文設計的針對日常卷煙產品質量反饋意見匯總的自動文摘系統,可以作為煙草行業分析卷煙產品質量反饋意見的有效工具。
參考文獻
[1] 吳杉杉,宋小倩. .NET框架介紹和WinCE開發環境搭建[J].中國新技術新產品,2011(6):95.
[2] 付明柏.基于.NET Framework的軟件復用技術研究[J].軟件導刊,2013(5):15-17.
[3] http://www.mandarintools.com/segmenter.html
[4] Feng Haodi, Chen Kang, Deng Xiaotie, et al. Accessor variety criteria for chinese word extraction[J]. Computational Linguistics,2004(30):75-93.
[5] 程娟.中文文檔自動摘要技術[D].濟南:山東大學,2006.
[6] 吳旭東.正向最大匹配分詞算法的分析與改進[J].科技傳播,2011(20):164-165.