
文獻標識碼: A
文章編號: 0258-7998(2013)05-0038-03
在圖形處理應(yīng)用中,圖形圖像數(shù)據(jù)的存取帶寬直接決定著整個圖形處理器的性能[1],因此,對圖形圖像數(shù)據(jù)的存取管理非常重要。參考文獻[2-3]對目前NVIDIA提出的統(tǒng)一計算設(shè)備架構(gòu)CUDA(Compute Unified Device Architecture)[4]中的存儲層次結(jié)構(gòu)做了介紹,但僅局限于從應(yīng)用層次上進行描述,并未對具體的圖形數(shù)據(jù)存取進行研究。參考文獻[5-6]對Neon圖形加速器進行了詳細的剖析,并從存儲架構(gòu)層次的角度介紹了Neon圖形加速器的存儲管理系統(tǒng)。Neon圖形加速器采用統(tǒng)一存儲系統(tǒng)模型,將所有圖形數(shù)據(jù)(如顏色、紋理圖像以及顯示數(shù)據(jù)等)進行統(tǒng)一管理。然而,Neon圖形加速器不提供對2維圖形圖像以及3維引擎中的緩沖區(qū)對象、顯示列表、頂點染色程序的支持。
并構(gòu)多核圖形處理器HMGPU(Heterogeneous Multi-core Graphic Processor Unit)是由西安郵電大學(xué)GPU團隊自主設(shè)計研發(fā)的異構(gòu)多核圖形處理器。通過對HMGPU的并行渲染架構(gòu)以及存儲數(shù)據(jù)進行分析,在參考文獻[5-6]的基礎(chǔ)上,本文設(shè)計并實現(xiàn)了HMGPU存儲管理系統(tǒng),將顯示存儲區(qū)與其他圖形存儲區(qū)劃分成兩個存儲區(qū),分別予以管理。同時,根據(jù)不同的圖形數(shù)據(jù)類型,分別進行存儲控制,為HMGPU提供了2 021.2 MB/s的存儲訪問速率。最后采用System Verilog進行行為模型建模,并驗證了其功能正確性。
1 HMGPU存儲管理系統(tǒng)總體分析
針對HMGPU圖形繪制任務(wù)并行實時處理的特點,兼顧效率與靈活性的具體需求,HMGPU存儲系統(tǒng)采用共享存儲模型實現(xiàn)對頂點數(shù)組、顯示列表、紋理貼圖、用戶加載程序/數(shù)據(jù)、2D圖形圖像等相關(guān)圖形數(shù)據(jù)的管理。其中顯示列表和頂點數(shù)組的數(shù)據(jù)一般不具有紋理貼圖、用戶加載程序以及2D圖形圖像數(shù)據(jù)的大片連續(xù)性。為了充分利用存儲空間,本存儲管理系統(tǒng)采用固定分區(qū)和分頁式分區(qū)兩種方式進行存儲管理;并利用片上存儲高性能的特性,將所有的管理控制信息存儲于片上存儲,用硬件管理方式實現(xiàn)存儲管理系統(tǒng),減少了圖形圖像數(shù)據(jù)的存取延遲,滿足HMGPU峰值為289.98 Mpixel/s像素填充率的性能要求。
2 HMGPU存儲管理系統(tǒng)設(shè)計
2.1 HMGPU存儲管理頂層設(shè)計
HMGPU存儲系統(tǒng)采用共享存儲結(jié)構(gòu),存儲空間主要劃分成獨立的染色程序區(qū)、2D圖形/圖像區(qū)、3D紋理貼圖區(qū)、用戶區(qū)4大塊。在圖形渲染過程中,渲染管線各部件以并發(fā)的方式訪問共享存儲。因此為了各個部件正確訪問存儲,對存儲內(nèi)部的讀寫操作采用互斥的方式來實現(xiàn)。同時,為了保證存儲管理對各渲染部件的實時響應(yīng),為每一個存儲訪問部件設(shè)定獨立的控制單元,當滿足突發(fā)傳輸條件時,向存儲管理仲裁部件發(fā)送訪問請求,由仲裁器仲裁,將存儲訪問權(quán)授予本次存儲訪問優(yōu)先級最高的渲染部件。HMGPU存儲管理系統(tǒng)的頂層框架設(shè)計如圖1所示。
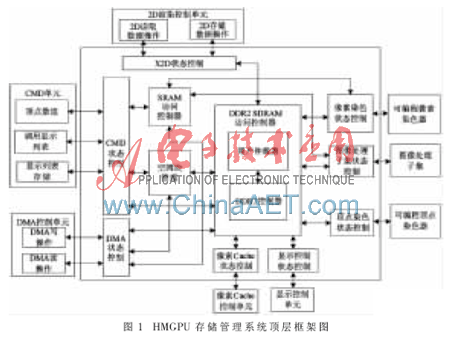
2.2 用戶區(qū)空閑塊的管理
在HMGPU中,對用戶區(qū)存儲空間的管理采用分頁式管理機制實現(xiàn),整個存儲空間以頁為單位進行分配和回收,每一存儲頁表示一個存儲塊。空閑區(qū)域由1 KB的空閑頁組成,并采用鏈表的方式進行連接,對空閑區(qū)域的管理實質(zhì)上就是對空閑鏈表進行管理。空閑區(qū)域鏈表具體結(jié)構(gòu)如圖2所示。對存儲空間的分配操作是:假設(shè)需要分配N頁存儲空間,按照鏈表的遍歷方式,從空閑鏈表表頭分配N頁存儲空間實現(xiàn)空間分配。類似的,對于空間回收,則將需要回收的空間鏈接至空閑鏈表的表尾從而實現(xiàn)空間回收。

2.3 分頁式數(shù)據(jù)對象管理
由于緩沖區(qū)對象與顯示列表數(shù)據(jù)的大小不定,在本存儲管理設(shè)計中采用分頁式存儲空間進行數(shù)據(jù)管理。
對于緩沖區(qū)對象以及顯示列表的管理,在片上SRAM中設(shè)定固定的8個塊用以存儲緩沖區(qū)對象的索引信息,設(shè)定256個塊用以存儲顯示列表索引信息。對于緩沖區(qū)對象以及顯示列表的存儲,則首先從空閑區(qū)獲取存儲空間,并將數(shù)據(jù)存儲至分配的鏈表中,將分配的存儲首地址、尾地址、數(shù)據(jù)大小以及對應(yīng)的參數(shù)信息根據(jù)標識號存儲至對應(yīng)的索引塊片上SRAM中。當對緩沖區(qū)對象或顯示列表進行調(diào)用時,首先根據(jù)標識號從對應(yīng)的索引塊中獲取存儲首地址、數(shù)據(jù)大小等參數(shù)信息,并根據(jù)偏移地址按照鏈表的遍歷方式從指定的地址開始返回被調(diào)用的數(shù)據(jù)信息,以此完成緩沖區(qū)對象與顯示列表的管理。
2.4 紋理對象與2D圖形圖像索引塊管理
紋理作為繪制更逼近真實場景的渲染數(shù)據(jù)信息之一,具有大片、連續(xù)等特征,其存儲空間一般都要求具有連續(xù)性。在HMGPU中,紋理采用固定分區(qū)形式進行連續(xù)存儲,紋理空間最多支持6幅紋理圖像,每一幅紋理共提供12層mipmap映射。對于每一幅紋理,在SRAM中均設(shè)有獨立且固定的索引塊。當接收到紋理創(chuàng)建請求時,首先根據(jù)紋理名字以及mipmap層次從片上SRAM中獲取該紋理數(shù)據(jù)的物理存儲地址,并將紋理數(shù)據(jù)存儲于指定的存儲空間,最后將對應(yīng)參數(shù)信息存儲于SRAM中以備后續(xù)訪問紋理使用。當需要進行紋理訪問時,類似于紋理的創(chuàng)建過程,首先從片上SRAM中獲取該紋理對應(yīng)的mipmap層的存儲首地址,并將其與偏移地址相加,獲取實際需要讀取的紋理數(shù)據(jù),最后返回給用戶端即完成紋理的訪問。
2D引擎中所需存儲于DDR2 SDRAM中的圖像包括源圖像、目標圖像、掩碼圖像、2D圖形等4類圖像。對于2D圖形圖像存儲與讀取,則根據(jù)2D引擎所發(fā)送的圖形圖像索引信息進行對應(yīng)的物理地址映射,并進行數(shù)據(jù)的存儲或者讀取。
2.5 頂點染色器與像素染色器染色程序索引塊
在HMGPU系統(tǒng)中,頂點染色器VS(Vertex Shader)以及像素染色器PS(Pixel Shader)均是可編程的。為了節(jié)省片上存儲空間,依據(jù)Cache與主存之間的存儲層次性原理,將大小固定的VS與PS染色程序存儲于DDR2中,備后續(xù)固定程序加載使用。以VS程序加載為例,在存儲中預(yù)定兩塊固定存儲空間,并按照乒乓方式進行染色程序的存儲與讀取,即每次存儲與讀取加載程序的存儲塊都是交替進行的,靈活而高效地實現(xiàn)染色程序的加載。
3 設(shè)計驗證和綜合
對所完成的HMGPU存儲管理系統(tǒng)的硬件電路進行具體設(shè)計,在Synopsys公司的VCS環(huán)境下進行了充分的功能仿真,并在DC環(huán)境下進行邏輯綜合,電路工作頻率達到167 MHz。同時,采用System Verilog語言,使用總線功能模型驗證方法構(gòu)建層次化的驗證環(huán)境,搭建自動化的驗證平臺,通過固定測試和隨機測試對各功能點進行測試。測試平臺如圖3所示。

測試平臺由輸入單元、輸出單元以及輸出響應(yīng)構(gòu)成,其中輸入單元采用總線功能模型驗證的方法產(chǎn)生不同的測試激勵,按照接口時序的要求將測試命令送到參考模型和待測試設(shè)計DUV(Design Under Verification)中;輸出單元比較參考模型輸出信號和DUV輸出信號,若結(jié)果不一致則打印錯誤報告同時結(jié)束仿真。
本文根據(jù)HMGPU的具體應(yīng)用需求,將存儲區(qū)劃分成顯示存儲區(qū)與其他圖形圖像數(shù)據(jù)區(qū)兩部分。對于每一類數(shù)據(jù),分別設(shè)定獨立控制模塊完成對該類數(shù)據(jù)的管理,并提供存儲系統(tǒng)的并發(fā)訪問,有效地實現(xiàn)了異構(gòu)多核圖形處理器的存儲管理系統(tǒng)。
整個系統(tǒng)采用Verilog語言實現(xiàn)其電路設(shè)計,并對電路進行了功能驗證與DC綜合以及FPGA驗證。結(jié)果表明,HMGPU存儲管理系統(tǒng)電路工作正常,且硬件電路具有良好的擴展性,實用性強,能夠滿足HMGPU存儲帶寬需求。本設(shè)計已經(jīng)應(yīng)用于自主研發(fā)的HMGPU中,協(xié)同其他部件完成圖形的渲染。
參考文獻
[1] COPE B,PETER Y K,LUK W.Using reconfigurable logic to optimise GPU memory accesses[C].Design,Automation and Test in Europe,DATE′08.Munich,2008:44-49.
[2] 馬安國,成玉,唐遇星,等.GPU異構(gòu)系統(tǒng)中的存儲層次和負載均衡策略研究[J].國防科技大學(xué)學(xué)報,2009,31(5):38-43.
[3] HENRY W,MISELMYRTO P,MARYAM S A,et al.Demystifying GPU microarchitecture through microbenchmarking[C]. Performance Analysis of Systems & Software,IEEE International Symposium on Computing & Processing(Hardware/Software),White Plains,NY,March 2010:235-246.
[4] NVIDIA Corporation.NVIDIA CUDA compute unified device architecture reference manual[EB/OL].(2008-06-xx)[2013-01-15].http://www.cs.ucla.edu/~palsberg/course/cs239/papers/CudaReferenceManual_2.0.pdf.1-247.
[5] MCCORMACK J,MCNAMARA R,GIANOS C,et al.Implementing neon:a 256-bit graphics accelerator[J].Micro IEEE,1999,19(2):58-69.
[6] MCCORMACK J,MCNAMARA R,GIANOS C,et al.Neon: A single-chip 3D workstation graphics accelerator,research report 98/1[C].HWWS′98 Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Workshop on Graphics Hardware. ACM,New York,NY,USA,1998:123-132.