
無論為數以百萬計的用戶搜索請求提供服務還是處理超大量的信息,都需要數量龐大的計算資源,進而消耗大量能源。事實上,用于計算與冷卻的能耗費用是數據中心運營的最大成本 [1]。隨著數據中心的數量和規模不斷增長,如果其能耗保持當前水平的話,那么預計數據中心的二氧化碳排放量到 2020 年將超過航空公司 [2]。因而亟需開發能夠處理巨量數據的低能耗解決方案。數據中心的環保化發展是互利共贏的,服務供應商不僅能夠顯著降低運營成本,同時還能最大限度減少對環境的影響。
FPGA 在加速 Web 搜索及類似信息檢索等常見數據中心工作任務方面擁有巨大的潛力,因為它具備固有的并行處理與低功耗優勢。充分認識到這一潛力的奧地利公司 Matrixware 購買了 FPGA 平臺,但缺乏自身實施復雜信息檢索應用的技術,因而公司聘請了我們聯合格拉斯哥大學 (University of Glasgow) 計算機系組建的團隊開發 FPGA 加速型專利搜索解決方案的概念驗證方案。該團隊成員包括三名設計人員和兼職助理研究員 Stelios Papanastasious,他們在信息檢索、FPGA 以及系統開發領域積累了豐富的專業知識,形成了一個開發原型應用所不可或缺的技能嫻熟的組合。經討論,大家一致同意采用 FPGA 加速型后端進行實時專利過濾應用的開發。
項目資源在人力和時間方面受到很大制約。因此,采用 HDL 實施過濾算法不可行,因而我們決定采用瑞典公司 Mitrionics 開發的高級編程解決方案。
原型應用在去年 11 月于奧地利維也納舉行的信息檢索設施研討會 (Information Retrieval Facility Symposium) 上引起了專利研究人員的極大興趣。處理數以百萬份的專利通常需要幾分鐘,但若采用 FPGA 加速型后端,幾秒鐘就能反饋結果。
我們在 2009 年 7 月舉行的 ACM SIGIR 國際信息檢索研究暨開發大會 (ACM SIGIR International Conference on Information Retrieval Research and Development) 上發布了結果,介紹了相關的性能提升情況 [3],并在 FPL 2009 國際現場可編程邏輯大會上對架構設計進行了詳細闡述 [4]。
文檔過濾的輸入與輸出
通常情況下,信息過濾任務是指檢查傳送進來的文檔是否與一系列既定的需求信息或配置文件相匹配 [5]。這種任務可在多種情況下出于多種原因而進行,例如,檢測傳送進入的電子郵件是不是垃圾郵件,比較專利申請是否與現有專利發生重疊,監控是否存在恐怖活動通信,監測并跟蹤新聞報道,等等。面對大量涌入的文檔,處理工作必須實時完成,從而確保時效性成為重中之重。鑒于此,我們的目標就是采用 FPGA 來實施完成計算強度最大的過濾應用,從而在節約時間和降低能耗的情況下提高文檔過濾的效率。
在本文中,我們將采用 Lavrenko 和 Croft 提出的相關性模型 [6]。這一理念適用于信息過濾任務,可通過生成概率語言模型確定傳入文檔是否與主題配置文件存在差異。如果文檔得分超過用戶定義的閾值,那么就視為與主題配置文件相關。
在 FPGA 上實施的算法表達如下:文檔可以建模為一個“詞袋”,即由(t,f )對組成的 D 集,其中 f=n(t,d),t 表示 t 這個詞在文檔 d 中出現的次數。配置文件 M 為一組對 p=(t,w),這里的 w 加權為:
![]()
給定文檔對于給定配置文件的得分計算為:
![]()
這里,T 是指在 D 和 M 中都出現的詞。該函數是大多數過濾算法的代表性內核算法,不同算法的主要區別在于配置文件中詞的加權。
應用架構
文檔過濾應用采用客戶端—服務器架構,其構成形式為將基于 GUI 的客戶端通過 TCP/IP 連接到通信服務器,該服務器可作為不同后端服務器和客戶端之間的代理(參見圖 1)。在典型的使用案例中,用戶首先向查詢服務器發出請求,常規搜索系統會返回選中排序列表。用戶隨后通過從該表中選擇相關文檔創建配置文件。接下來,配置文件服務器使用所有合并文檔的完整文本構建配置文件(即詞和加權列表)。配置文件服務器將該配置文件與完整的文檔集合進行匹配,并向客戶端返回分數流。
模塊化的客戶端—服務器架構有助于建立系統基準,因為我們可以在主機 CPU 上方便地添加配置文件服務器的 C++ 參考實施。如圖 1 所示,應用由 FPGA 加速的部分受限于計算強度最大的任務,也就是文檔與配置文件的匹配。主機系統則負責處理所有其他的任務(參見圖 2)。
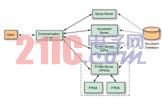
圖 1 —— 系統架構以可作為客戶端與后端服務器之間代理的通信服務器為中心。
配置文件服務器根據從客戶端獲得的配置文件過濾一系列文檔,并返回分數流。為了評估性能,我們同時創建了 C++ 參考實施和 FPGA 加速實施方案。兩種版本的實施方案基本功能相同,都能通過 TCP/IP 接口接收構成配置文件的文檔列表,用相關性模型構建配置文件,并根據該配置文件對存儲器緩沖的文檔進行評分,從而通過 TCP/IP 向客戶端返回文檔分數流。可在存儲器中緩沖文檔流,否則會由于緩慢的磁盤存取影響應用的性能。
我們在具有兩個 RC100 刀片的 SGI Altix 4700 設備上實施該應用,其中的每個刀片都包含兩個運行頻率為 100 MHz 的賽靈思 Virtex®-4 LX200 FPGA;每個 FPGA 都通過 SGI NUMAlink 高速I/O 接口連接到主機平臺,并能通過最高速度為每秒 16GB 的 128 位數據總線存取本地 64MB 的SRAM 存儲庫。主機系統是一套 80 個內核的 64 位 NUMA 設備,運行性能為 64 位 Linux (OpenSuSE)。處理器為雙核 Itanium-2,運行頻率為 1.6 GHz,其中每個處理器都能直接存取 4GB 的存儲器,而且能通過 NUMAlink 存取完整的 320GB 存儲器空間。值得注意的是,Itanium 處理器功耗約為 130 瓦特 [7],而每個 Virtex-4 FPGA 的功耗僅約 1.25 W [8]。
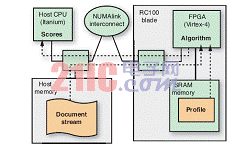
圖 2 —— 在 FPGA 子系統架構中,Virtex-4 器件通過 SGI 的 NUMAlink 接口與主機平臺連接。
對于 C++ 語言應用而言,我們實施 Lemur 信息檢索 (IR) 框架,對于與 FPGA 應用的交互,我們則使用 SGI 可配置專用計算 (RASC) 庫。Lemur Toolkit(詳情訪問 www.lemurproject.org)是一套開源工具集,專為 IR 研究而精心設計,可支持索引以及多種相關性和檢索模型。RASC 庫是 SGI的專有解決方案,能夠通過高性能 NUMAlink 互連機制將 FPGA 與主機系統相集成。RASC 庫定義的硬件抽象 API 可控制系統中的所有硬件元素。
我們用 Mitrionics 軟件開發工具套件 (SDK) 將特定域的 Mitrion-C 語言轉換為 VHDL。生成的VHDL 現在能夠方便地指向 FPGA 器件架構。我們采用帶 XST 合成工具的賽靈思 ISE® 工具鏈來創建 Virtex-4 比特流。
高級 FPGA 編程
Mitrionics SDK 可提供 Mitrion-C 作為高級語言,專用于滿足在 FPGA 上快速開發應用之需。不過,作為后綴的 C 有些誤導作用。盡管這種語言采用了 C 風格的語法,但實際上是一種遵循函數編程風格的單賦值數據流語言。Mitrion-C 原生支持廣泛(矢量)而深入(管道)的并行功能,因而非常適用于處理數據流的算法,例如過濾以及其他眾多類型的文本和數據挖掘算法等。
Mitrion-C 還提供了一種流數據類型,可配合 foreach looping 構造實現流水線操作;此外,還提供矢量數據類型以支持數據并行工作,以及支持順序列表的列表數據類型。具體而言,用戶可過濾foreach loop 的流輸出,生成較小的流,如以下 Mitrion-C 代碼示例所示。此外,程序人員還能用元組結構 (tuple construct) 創建功能強大的數據類型。最后還有一個需要指出的特性是,該語言能支持可變寬度整數和浮點數。


為了在 FPGA 上高效實施評分操作,我們必須解決的關鍵問題是高效查詢配置文件以及文檔流的高效 I/O 流。
對于文檔中的每個詞,應用都要查詢配置文件中相應的詞并獲得詞加權 (term weight)。由于大多數查詢都找不到結果(即大多數文檔的大多數詞不會出現在配置文件中),因此必須首先丟棄否定詞。鑒于此,我們在 FPGA Block RAM 中采用了 Bloom 過濾器 [9]。BRAM 的內部帶寬越高,拒絕否定詞的結果就越快。由于需要查詢,因此配置文件必須作為某種散列函數進行實施。不過,由于配置文件的大小不能提前知道,因而我們不可能構建出完美的散列函數。不完美的散列函數會出現沖突問題,進而降低性能。
為了解決這一問題,我們采用了分檔方案,即將外部 SRAM 分區為 bin,每個 bin 都可包含固定數量的配置文件詞。Bin 的大小決定了可處理的沖突數。如需給 bin 分配配置文件詞,只需將詞 ID 的較下部分作為存儲器地址,從而避免了實際的散列操作。
讓 SRAM 存儲器容量設定為 NM 配置文件詞。詞 ID 是一個無符號的整數,其范圍取決于詞匯量,就我們的例子而言約為 400 萬個詞,需要 24 位。詞加權為 8.32 定點數,因而配置文件詞需要 64 位。RC100 上的 SRAM 包括 4 個 16 MB 存儲庫,因此 NM=223。Bins 的數量 nb=NM/b 和 bin 地址用詞 ID“t”進行計算,即 (t&(nb-1)).b。
Bin 的占用概率 x 由組合決定,置換決定 bin 的數量 nb 和描述詞的數量 np。這樣,我們就能計算 bin 溢出的概率就是 bin 大小的函數(即 bin 的數量),即 NM=b.nb。bin 尺寸越大,查詢就越慢,但是,由于 SRAM 存儲庫包括 4 個獨立的 64 位可尋址雙端口 SRAM,我們實際上可以并行查詢四個配置文件詞。因此,相對性能會降低 1/ceil(b/4)。我們的分析結果顯示,即便對最大型的配置文件來說(16K,我們研究所用的最大配置文件為 12K,不過通常配置文件比這都要小得多),b=4時(最佳性能),bin 溢出概率為 10-9。換言之,描述詞被丟棄的概率不到 10 億分之一。應注意的是,由于我們假定詞匯量無限大,因而這一估算還是保守數字。
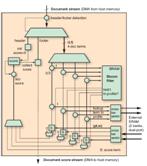
圖 3 —— 過濾應用的 FPGA 實施示意圖
通過將文檔表述為“詞袋”,文檔流就是文檔 ID、文檔詞對組 (document term pair set) 等對列表。從物理上說,FPGA 以每秒 1.6 GB 的速度從 NUMAlin 接受 128 位字流。因此,文檔流必須在字流上編碼。可將文檔詞對 di =(ti,fi) 編碼為 32 位:24 位用于詞 ID(支持 1,600 萬個詞的詞匯庫),8 位用于詞的頻率。這樣,我們就能將 4 個對組合到 128 位字中。要標示文檔的起點與終點,我們需要插入包含文檔 ID(64 位)和標志符(64 位)的報頭與腳注字 (footer word)。
如上所述采用查詢表架構和文檔流格式,實際的查詢和評分系統(圖 3)會非常直接。我們只需掃描輸入流以檢查報頭和腳注字即可。報頭字將文檔得分設為 0,而腳注字則收集并輸出文檔得分。對于文檔中的每四個配置文件詞,Bloom 過濾器首先丟棄否定詞結果,再從 SRAM 讀取四個配置文件詞。并行計算并添加(圖 4)每個詞的得分。實際上,四分之三的配置文件詞 ID 不會匹配于文檔詞 ID;只對第四個進行實際計算。將文檔中所有詞的得分進行累加,最后得分流在輸出到主機存儲器之前與限值進行比較過濾。
主機—FPGA 接口將文檔流從存儲器緩沖器中傳輸至 FPGA,并將得分流返回至客戶端中。一旦從客戶端接收到配置文檔 ID 表,子進程即從主進程中分叉出來,以構建實際的配置文件,將其載入 SRAM 并在 FPGA 上運行算法。每個子進程都會產生一個獨立的輸出線程,以對從 FPGA 獲得的得分進行緩沖,并通過 TCP/IP 將這些得分傳輸到客戶端,從而使用網絡對得分流進行多路復用。若沒有該線程,網絡吞吐量的波動就會降低系統性能。這種主機接口架構的主要優勢在于,它具有很高的可擴展性,能輕松滿足大量 FPGA 的需求。
大幅度提速
為了評估 FPGA 加速型過濾應用的性能,我們進行了一系列實驗,將基于 FPGA 的實施方案與采用 C++ 編寫的運行于 Altix 之上的優化參考實施方案進行了比較。在比較過程中,我們使用了三個 IR 測試集合(參見表 1):一個是文本檢索會議 (TREC) 提供的基準參考集合 TREC Aquaint,還有兩個分別是美國專利與商標署 (USPTO) 和歐洲專利署 (EPO) 提供的專利集合。我們選擇上述測試集合來評估不同文檔長度和大小對過濾時間的影響。
|
集合 |
文檔數 |
平均文檔長度 |
平均獨有名詞 |
|
Aquaint |
1,033,461 |
437 |
169 |
|
USPTO |
1,406,200 |
1,718 |
353 |
|
EPO |
989,507 |
3,863 |
705 |
表 1——集合統計
為了仿真眾多不同的過濾器,我們通過選擇隨機文檔并用標題作為請求,隨后再選擇請求服務器返回的固定數量的文檔作為偽相關文檔,來為每個測試集合構建配置文件。我們接下來使用返回的文檔構建相關性模型,該模型定義了文檔集合中每個文檔應當匹配(就好像從網絡進行流處理一樣)的配置文件。配置文件中的文檔數量從 1 到 50 不等,可確定增加配置文件的大小(詞數和文檔數)會對性能有何影響。我們將上述進程重復 30 次,并計算平均處理時間。
我們在表 2 和圖 5 中對有關結果進行了總結。從表中可以清晰地看出,FPGA 實施方案在速度方面通常比標準實施方案快一個數量級。從圖中可以看出,配置文件大小(需要匹配的詞數)增加后,標準實施方案變得越來越慢,而 FPGA 實施方案的速度相對保持不變。這是因為 FPGA 實施方案支持配置文件評分的流分線操作,這樣無論配置文件大小如何,時延基本保持不變。
這些結果清晰表明,FPGA 對加速 IR 任務有著巨大的潛力。FPGA 的提速幅度已然相當大(特別對大型配置文件而言尤其明顯),而且仍有進一步提高的空間。通過仿真,我們確認 FPGA 算法給一個文檔詞評分需要兩個時鐘周期。制約因素為每周期 128 位的 SRAM 存取速度,這需要兩個周期才能讀取四個配置文件詞。如果時鐘速度為 100 MHz,則意味著 FPGA 能在 15 秒之內完成整個 EPO 文檔集合的評分。當前應用在四個 FPGA 上需要約 8.5 秒,因此原則上我們至少可以讓性能再翻一番。
差異的原因在于 I/O 流 (streaming I/O):通過主機操作系統設備驅動器可將文檔流從用戶存儲器空間傳輸至 NUMAlink,這需要直接存儲器存取 (DMA) 傳輸。驅動器可傳輸流的緩存模塊。目前,對所傳輸模塊的大小來說,這一傳輸并不是以最優的方式實施的,進而導致無法達到最高吞吐量。此外,用獨立的線程進行傳輸排序也能避免傳輸時延。
遇到的問題和吸取的經驗
這一項目的意義不僅在于它展示了 FPGA 作為信息檢索任務加速器的優勢,而且還為我們提供了 FPGA 加速系統軟硬件要求的重要信息。
至主機系統的 I/O 是確保性能的關鍵:NUMA 存儲器與 FPGA 之間的 DMA 機制必須獲得 Mitrionics SDK 和 SGI RASClib 的支持。在此前的項目中,我們必須先將數據傳輸到電路板上的 SRAM 中才能進行處理,但這會嚴重影響性能,因為數據的載入和結果的卸載會造成非常大的開銷。此外,我們也清晰地認識到,IR 任務尤其需要大量的片上和板上存儲器,才能實現效率最大化。
此外,為了充分使用 FPGA,未來的平臺必須具備兩個重要特性,一是必需能在 FPGA 之間直接傳輸數據,二是必需能夠關閉主機處理器(或用一個主機處理器控制多個 FPGA)。關閉主機處理器的功能尤其重要:在 Altix 平臺上,即便 Itanium 處理器完全處于空閑狀態也不能關閉。但是,空閑的 Itanium 處理器的功耗也高達工作狀態下所需功耗的 90%。因此,盡管 FPGA 加速的節能效果明顯,但我們目前的系統即便在加速器運行過程中主機存儲器空閑狀態下,其總體節能作用仍然有限。
開發 FPGA 加速型系統的另一重要領域就是軟件。我們的經驗明確反映出,主要的復雜問題在于FPGA 和主機系統之間的接口連接:Mitrion-C 中的實際 FPGA 應用開發效率非常高;采用 Lemur 工具套件構建查詢和服務文檔的框架也相對容易開發。但是,采用 RASClib 開發連接主機應用和FPGA 接口的代碼非常復雜,而且由于并發性問題,還非常難以調試。因而,接口代碼的開發占據了絕大部分的開發時間。
|
集合 |
配置文件文檔數 |
處理器獨有名詞數 |
CPU(秒) |
FPGA(秒) |
增益 |
|
Aquaint |
1 |
254 |
21.3 |
2.6 |
8.3x |
|
10 |
1,444 |
27.4 |
2.6 |
10.5x |
|
|
50 |
4,713 |
34.5 |
2.6 |
13.2x |
|
|
USPTO |
1 |
28 |
64.0 |
7.2 |
8.9x |
|
10 |
148 |
68.3 |
7.1 |
9.6x |
|
|
50 |
615 |
76.9 |
7.5 |
10.3x |
|
|
EPO |
1 |
1,327 |
107.3 |
8.4 |
12.7x |
|
10 |
4935 |
153.3 |
8.1 |
19.0x |
|
|
50 |
12,314 |
177.1 |
8.5 |
20.8x |
表 2 —— 性能統計數據

圖 5 —— 時間(秒)和配置文件中文檔數量的對比圖
FPGA 高級編程的最后一個問題是編譯速度。習慣于 C++ 或 Java 等語言的開發人員認為即便應用非常復雜,構建時間也應該比較短。除了最基本的設計之外,當前的 FPGA 工具執行綜合以及放置路由工作幾乎都需要一整天的時間。非常長的構建時間會嚴重影響工作效率,因而時間應當縮短到一般性軟件構建時間,這樣才能使 FPGA 加速更具吸引力。
定制硬件平臺
我們用這個項目探討了 FPGA 加速的可能性,并展示了 FPGA 作為數據中心綠色環保技術的巨大潛力。我們希望進一步擴展這項研究,調查文檔處理所需的全系列工作任務,如語法分析、詞干、索引、搜索以及過濾等。我們清楚地認識到,現有系統在節能潛力方面很有限,我們希望研究能以業界最高效率專門執行信息檢索任務的可定制硬件平臺。這樣,我們就能顯著加速算法的執行,同時大幅度降低能耗,從而開發出更加環保、速度更快的數據中心。