
摘 要: 在深入分析Turbo譯碼算法" title="譯碼算法">譯碼算法的基礎(chǔ)上,采用MAX-LOG-MAP" title="MAX-LOG-MAP">MAX-LOG-MAP算法進(jìn)行了Turbo碼譯碼器" title="譯碼器">譯碼器的FPGA設(shè)計(jì)與實(shí)現(xiàn),并給出相應(yīng)實(shí)現(xiàn)參數(shù)和結(jié)構(gòu)。對(duì)FPGA的實(shí)現(xiàn)與MATLAB浮點(diǎn)算法做了仿真比較。
關(guān)鍵詞: Turbo碼 MAX-LOG-MAP算法 FPGA
Turbo碼自1993年提出以來(lái)[1],由于其接近香農(nóng)極限的優(yōu)異譯碼性能,一直成為編碼界研究的熱點(diǎn)。近年來(lái),用戶(hù)對(duì)通信質(zhì)量的要求越來(lái)越高,學(xué)者們已將研究重點(diǎn)從理論分析轉(zhuǎn)移到Turbo碼的實(shí)用化上來(lái)。Turbo碼現(xiàn)已成為深空通信的標(biāo)準(zhǔn),即第三代移動(dòng)通信(3G)信道編碼方案[2]。
Turbo碼雖然具有優(yōu)異的譯碼性能,但是由于其譯碼復(fù)雜度高,譯碼延時(shí)大等問(wèn)題,嚴(yán)重制約了Turbo碼在高速通信系統(tǒng)中的應(yīng)用。因此,如何設(shè)計(jì)一個(gè)簡(jiǎn)單有效的譯碼器是目前Turbo碼實(shí)用化研究的重點(diǎn)。本文主要介紹了短幀Turbo譯碼器的FPGA實(shí)現(xiàn),并對(duì)相關(guān)參數(shù)和譯碼結(jié)構(gòu)進(jìn)行了描述。
1 幾種譯碼算法比較
Turbo碼常見(jiàn)的幾種譯碼算法中,MAP算法[1][3]具有最優(yōu)的譯碼性能。但因其運(yùn)算過(guò)程中有較多的乘法和指數(shù)運(yùn)算,硬件實(shí)現(xiàn)" title="硬件實(shí)現(xiàn)">硬件實(shí)現(xiàn)很困難。簡(jiǎn)化的MAP譯碼算法是LOG-MAP算法和MAX-LOG-MAP算法,它們將大量的乘法和指數(shù)運(yùn)算轉(zhuǎn)化成了加減、比較運(yùn)算,大幅度降低了譯碼的復(fù)雜度,便于硬件實(shí)現(xiàn)。簡(jiǎn)化算法中,LOG-MAP算法性能最接近MAP算法,MAX-LOG-MAP算法次之,但由于LOG-MAP算法后面的修正項(xiàng)需要一個(gè)查找表,增加了存儲(chǔ)器的使用。所以,大多數(shù)硬件實(shí)現(xiàn)時(shí),在滿(mǎn)足系統(tǒng)性能要求的情況下,MAX-LOG-MAP算法是硬件實(shí)現(xiàn)的首選。通過(guò)仿真發(fā)現(xiàn),采用3GPP的編碼和交織方案[2],在短幀情況下,MAX-LOG-MAP算法同樣具有較好的譯碼性能。
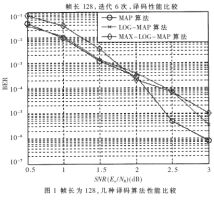
如圖1所示,幀長(zhǎng)為128,迭代6次,BER=10-5的數(shù)量級(jí)時(shí), MAX-LOG-MAP算法的譯碼性能比MAP算法差大約0.6dB,比LOG-MAP算法差0.2dB左右。所以,本文采用3GPP的交織和(13,15)編碼方案,MAX-LOG-MAP譯碼算法進(jìn)行短幀Turbo碼譯碼器的FPGA實(shí)現(xiàn)與設(shè)計(jì)。
2 MAX-LOG-MAP算法
為對(duì)MAP算法進(jìn)行簡(jiǎn)化,通常將運(yùn)算轉(zhuǎn)換到對(duì)數(shù)域上進(jìn)行,避免了MAP算法中的指數(shù)運(yùn)算,同時(shí),乘法運(yùn)算變成了加法運(yùn)算,而加法運(yùn)算用雅可比公式簡(jiǎn)化成MAX*運(yùn)算[4]。
將運(yùn)算轉(zhuǎn)化到正對(duì)數(shù)域進(jìn)行運(yùn)算,則MAX*可等效為:
按照簡(jiǎn)化公式(3)對(duì)MAP譯碼算法[1][3]的分支轉(zhuǎn)移度量、前向遞推項(xiàng)、后向遞推項(xiàng)及譯碼軟輸出進(jìn)行簡(jiǎn)化。
分支轉(zhuǎn)移度量:

為防止迭代過(guò)程中數(shù)據(jù)溢出,對(duì)前后向遞推項(xiàng)(5)、(6)式進(jìn)行歸一化處理:
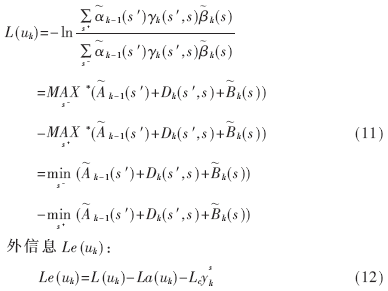
3 FPGA實(shí)現(xiàn)關(guān)鍵技術(shù)
3.1 數(shù)據(jù)量化
在通信系統(tǒng)中,譯碼器的接收數(shù)據(jù)并不是連續(xù)不變的模擬量,而是經(jīng)過(guò)量化后的數(shù)字量。接收數(shù)據(jù)的量化會(huì)引入量化噪聲,從而影響譯碼的性能。所以,接收數(shù)據(jù)量化的精度直接影響到譯碼的性能。由參考文獻(xiàn)[5~6]可知,采用3位量化精度就能得到與沒(méi)有經(jīng)過(guò)量化的浮點(diǎn)數(shù)據(jù)相近的譯碼性能。為了簡(jiǎn)化FPGA的設(shè)計(jì),本文采用了統(tǒng)一的定點(diǎn)量化標(biāo)準(zhǔn)F(9,3),即最高位為符號(hào)位,整數(shù)部分8位,小數(shù)部分3位。由此,前后遞推項(xiàng)(9)、(10)式的初始值可表示為:

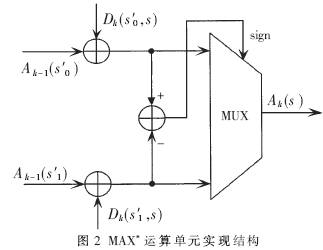
3.2 MAX*運(yùn)算單元
由前面的MAX-LOG-MAP算法介紹可知,MAX*運(yùn)算單元是整個(gè)譯碼的主要運(yùn)算單元,它與viterbi譯碼的ACS(加比選)運(yùn)算單元一樣,先分別進(jìn)行加法操作,然后對(duì)所得結(jié)果進(jìn)行比較,最后將較小的一個(gè)結(jié)果作為運(yùn)算結(jié)果輸出。實(shí)現(xiàn)結(jié)構(gòu)如圖2所示。
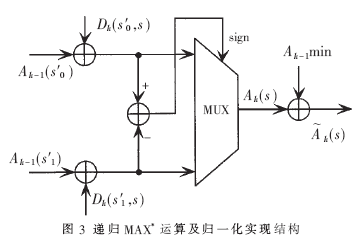
3.3 前后向遞推運(yùn)算單元
由公式(5)~(8)可知,前后向遞推單元除了需要進(jìn)行MAX*與運(yùn)算外,還需要進(jìn)行歸一化處理。為得到較快的運(yùn)算速度,首先,計(jì)算上一時(shí)刻所有狀態(tài)的最小值,然后對(duì)當(dāng)前時(shí)刻的每一狀態(tài)進(jìn)行MAX*運(yùn)算,并將運(yùn)算結(jié)果減去上一時(shí)刻的最小狀態(tài)值" title="狀態(tài)值">狀態(tài)值,即得到當(dāng)前時(shí)刻遞推各狀態(tài)的歸一化值。實(shí)現(xiàn)結(jié)構(gòu)如圖3所示。
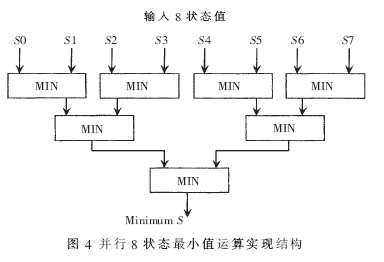
3.4 8狀態(tài)值最小值運(yùn)算單元
由MAX-LOG-MAP算法可知,在進(jìn)行前后向遞推歸一化處理和計(jì)算譯碼軟輸出時(shí),均需要計(jì)算每一時(shí)刻8個(gè)狀態(tài)的最小值。為了減小計(jì)算延時(shí),采用了8狀態(tài)值并行比較的結(jié)構(gòu),與串行的8狀態(tài)值比較結(jié)構(gòu)相比較,要少4級(jí)延時(shí)。實(shí)現(xiàn)結(jié)構(gòu)如圖4所示。
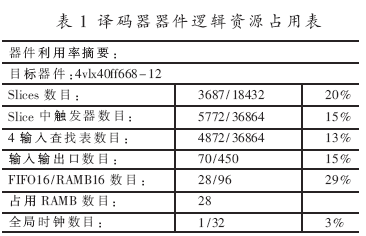
4 仿真結(jié)果
按照以上所分析的簡(jiǎn)化譯碼算法、FPGA實(shí)現(xiàn)的相關(guān)參數(shù)和結(jié)構(gòu),整個(gè)譯碼采用Verilog HDL語(yǔ)言編程,以Xilinx ISE 7.1i、Modelsim SE 6.0為開(kāi)發(fā)環(huán)境,選定Virtex4芯片xc4vlx40-12ff668進(jìn)行設(shè)計(jì)與實(shí)現(xiàn)。整個(gè)譯碼器占用邏輯資源如表1所示。
MAX-LOG-MAP譯碼算法,幀長(zhǎng)為128,迭代4次的情況下,MATLAB浮點(diǎn)算法和FPGA定點(diǎn)實(shí)現(xiàn)的譯碼性能比較如圖5所示。
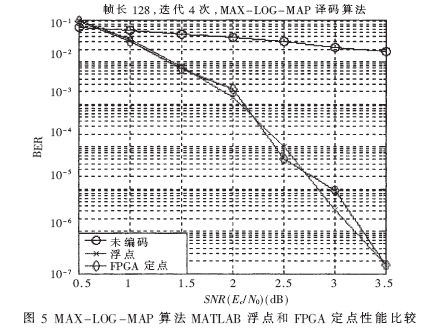
由MAX-LOG-MAP算法的MATLAB浮點(diǎn)與FPGA定點(diǎn)的性能比較仿真結(jié)果可知,采用F(9,3)的定點(diǎn)量化標(biāo)準(zhǔn),F(xiàn)PGA定點(diǎn)實(shí)現(xiàn)譯碼性能和理論的浮點(diǎn)仿真性能基本相近,并具有較好的譯碼性能。
綜上所述,在短幀情況下,MAX-LOG-MAP算法具有較好的譯碼性能,相對(duì)于MAP,LOG-MAP算法具有最低的硬件實(shí)現(xiàn)復(fù)雜度,并且Turbo碼譯碼延時(shí)也較小。所以,在特定的短幀通信系統(tǒng)中,如果采用Turbo碼作為信道編碼方案,MAX-LOG-MAP譯碼算法是硬件實(shí)現(xiàn)的最佳選擇。
參考文獻(xiàn)
[1] BERRON C, GLAVICUS A, THITIMAAJSHIMA P. Near shannon limit error-correcting coding and decoding: Turbocodes(1) [C]. ICC’93,1993:1064-1074.
[2] ?3GPP TS 25.212 Release6. Multiplexing and channel coding (FDD) [S], 2005.
[3] ?王新梅,肖國(guó)鎮(zhèn).糾錯(cuò)碼—原理與方法[M].西安:西安電子科技大學(xué)出版社,2001.
[4] ?ROBERTSON P, VILLEBRUN E, HOELER P. A comparison of optimal and sub-optimal MAP decoding algorithms operating in the log domain [C]. ICC.1995,1995:1009-1013.
[5] ?MONTORSI G, BENEDETTO S. Design of fixed-point iterative decoders for concatenated codes with interleavers. IEEE Journal on Selected Areas in Communications,2001:871-882.
[6] ?WU Yu Fei, WOERNER B D, BLANKENSHIP T K. Data ?width requirements in SISO decoding with module normalization. IEEE Trans. On Commun, 2001,(49)11.