
摘? 要: 小波" title="小波">小波分析是信息處理領域的一種重要處理方法,但是小波分解巨大的運算量卻嚴重束縛了其在實時處理領域中的應用。提出了一種基于FPGA實現的高速小波分解方法,該方法采用新的小波分解結構,使多層分解得以同時進行,從而使小波分解的速度達到高速輸入圖像的數據率;并適當選取了數據結構,使得經分解、重構" title="重構">重構后所得圖像的峰值信噪比達到無窮大。這種方法大大提高了硬件系統進行小波分解的速度,在小波分解的性能和硬件實現的資源消耗上找到了一個較優的結合點。
關鍵詞: 小波分析? 圖像處理? 圖像壓縮? 實時處理? FPGA
?
目前,小波分析在許多科學與工程領域中得到了廣泛研究和應用。由其引出的多分辨分析方法,更是成為圖像壓縮、圖像分割、特征提取、語音識別等方面的一種有力工具。但是,隨著它在實際工程中應用的不斷深入,研究人員發現,在數據速率很高的情況下,現有的硬件系統很難承擔實時處理的巨大運算量。因此,研究適合硬件實現的小波分解算法和改進小波分解的硬件實現方法" title="實現方法">實現方法,便成為小波分析應用于工程實際的兩大關鍵課題。
本文將闡述一種基于FPGA(現場可編程邏輯陣列)芯片實現的高速圖像小波分解方法,較好地解決了運算量大和要求實時處理的矛盾。
1 二維小波分解和重構算法
1.1 Mallat算法
當前,在小波分析的研究領域,通常采用多分辨分解和合成的金字塔算法,即Mallat算法。Mallat算法的基本思想是:將一個分辨率為1的原始信號F(n)進行N層分解,分解成一個分辨率為2-N的低頻信號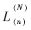 和一系列高頻信號
和一系列高頻信號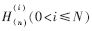 。其流程如圖1所示。
。其流程如圖1所示。
?

?
分解算法的公式如下:

重構算法是分解過程的逆過程,經過逆濾波就能恢復出原始的信號序列。
重構算法的公式如下:
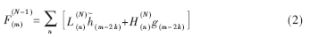
1.2 二維Mallat算法
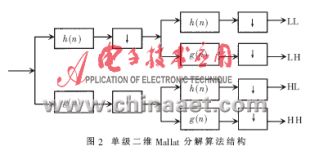
在圖像處理領域,需要進行處理的通常是二維圖形。因此,將Mallat算法擴展到二維空間,適當地選取一組行和列變換正交的小波系數,對圖像(或分解后的低頻子圖)分別進行行變換和列變換。然后,根據后續的具體應用對N次分解所得的圖像在不同的分辨率下進行分析、處理或數據壓縮。二維Mallat算法的結構如圖2所示。
?
1.3 CDF9/7系數
在進行二維Mallat分解時需選取一組正交的小波系數。經過小波算法研究人員的多年研究,目前已經找出了多組小波系數。其中以CDF9/7系數應用最為普遍,已成為JPEG2000圖形壓縮標準推薦使用的系數。但是,CDF9/7系數通常采用浮點進行計算,在進行高速處理時不便于硬件實現。因此,選取α=0.5的CDF9/7系數,如公式(3)和(4)所示,濾波器的系數可以表示成分母為2的冪、分子為2的冪之和的形式,在保證小波分解性能的情況下更適合用FPGA實現。
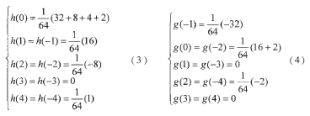
1.4 圖像的邊緣延拓
對圖像進行行或列分解可以看成是一個對有限長序列進行濾波的過程,在行變換和列變換時需要進行首尾數據延拓。常用的延拓方式包括:對稱延拓、“0”延拓、恒等延拓、周期延拓等。經多次實驗證明,圖像恢復效果以對稱延拓為最好,而且實現也比較方便。
2 普通的FPGA實現方法
在數據輸入速率很高(100MHz量級)、系統連續工作的情況下,要實時地完成小波分解,需要即時完成大量的乘法和加法運算、數據讀寫操作等。只支持單流水線工作的普通DSP系統在數據處理" title="數據處理">數據處理時受處理器頻率、數據輸入輸出帶寬等因素的限制,而支持并行處理的高性能DSP在算法的分割、數據交換上存在較大的困難。因此,在進行高速數據處理時,通常基于FPGA設計一個可以并行運算的專用處理器,從而達到較高的數據處理速度。
目前,在工程領域通常采用順序逐級分解的方法。即在對圖像進行緩沖后,逐次在FPGA中進行各級的行變換和列變換。其系統結構如圖3所示。
?
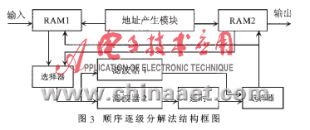
這種結構的主要優點是占用的FPGA資源較少。但這種設計方法的致命缺陷是,每次處理都必須將各級分解作完,才能對下一幀圖像進行處理。限于FPGA和RAM的接口帶寬,其處理速度不可能太高,而且占用的外部RAM空間較大。
3 改進的FPGA實現方法
針對普通的順序逐級分解方法的缺陷,充分利用Xilinx公司VertixE系列FPGA的特性,設計一種數據串行輸入(不需進行幀緩沖)、多級變換同時進行的結構,可以大大提高整個小波分解系統的數據處理速度并節省大量的外部RAM空間。
3.1 FPGA內部的功能劃分
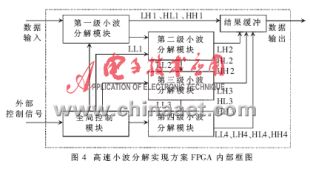
本方法主要是利用VirtexE系列FPGA內部有大量Block RAM資源和邏輯資源的特點,直接在FPGA內部進行多級分解。按邏輯功能的不同,FPGA內部將實現如圖4所示的幾個功能模塊。
?
?
全局控制模塊接收外部控制信號(芯片使能、數據時鐘等),由內部計數器進行計時、產生各級分解模塊的控制信號(模塊使能、起始終止信號等)。各級分解模塊則在全局控制模塊的控制下,對外部數據或前一級的LL輸出數據進行鎖存、處理、緩沖、輸出等操作。
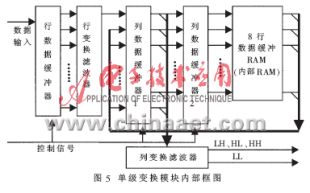
圖4中的每一級小波分解模塊需要完成圖像的行和列兩次變換。如果選擇先進行完整的行變換再進行列變換的方法,將需要大量的緩沖空間并且需要更多的時鐘周期。因此,必須采用行變換和列變換同時進行的形式,如圖5所示。圖像數據輸入到分解模塊的數據輸入端,由行數據緩沖器進行移位、鎖存。鎖存后的數據并行輸出到行變換濾波器,進行低通和高通濾波,然后進行抽樣、緩沖輸出。行濾波器的輸出與存儲在8行數據緩沖RAM內相同位置的數據鎖存到列數據緩沖器1中。緩沖器1的輸出與列變換濾波器的輸入相連,時間靠后的8個數據被鎖存到列數據緩沖器2。列數據緩沖器2的數據將送到內部RAM進行緩沖,下一個行周期將前8個數據輸出到列緩沖器1,從而實現列方向上的數據移位。列變換濾波器輸出的LH、HL、HH直接或經緩沖后輸出,LL則輸出到下一級分解模塊進行處理。
?
本方法相對普通實現方法的主要優勢在于:首先,在分解過程中數據的存儲在片內進行,不受芯片接口帶寬的限制,數據交換速度達到最快;其次,多級分解同時進行,進一步提高了分解的整體速度;再次,中間數據不必輸出片外,節省了外部RAM的空間。此外,在FPGA的設計過程中還加入了流水線、分布式算術[3~4]等優化技術,進一步提高了FPGA器件進行小波分解的速度。
3.2 中間數據動態范圍" title="動態范圍">動態范圍及精度
在進行FPGA設計時,為了保持中間數據長度一定,每次變換完成后都必須進行數據的首尾截取,中間結果的數據動態范圍和數據精度將直接影響到分解的效果和硬件的開銷。動態范圍不夠,將出現數據溢出,動態范圍選取過大又會浪費硬件資源。保留中間結果的精度將直接影響到分解后數據的有效性。
3.2.1 動態范圍分析
根據公式(3)、(4)中選取的CDF9/7系數h(n)和g(n),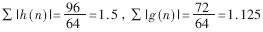 ,以最壞的情況計算,數據動態范圍每次變換擴大到原來數據范圍的1.5倍。經8次變換(4層分解,每層兩次變換)后,數據的動態范圍將擴大到原來的(1.5)8≈25.63倍。若圖像的原始數據為8位,要含蓋所有的情況則需要用13位表示整數。
,以最壞的情況計算,數據動態范圍每次變換擴大到原來數據范圍的1.5倍。經8次變換(4層分解,每層兩次變換)后,數據的動態范圍將擴大到原來的(1.5)8≈25.63倍。若圖像的原始數據為8位,要含蓋所有的情況則需要用13位表示整數。
3.2.2 累計截尾誤差分析
設每次中間結果保留n位小數,則截尾引起的誤差為:Δx=2-(n+1)。經過8次變換,每次變換的截尾誤差會逐級累加放大,最壞情況的累計誤差為:Δx(8)=Δx=(1+1.5+1.52+…+1.57)。考慮到第一次進行運算的數據小數部分為0,而且每次變換要除以64(2的6次冪),若小數位數大于等于6位,則第一次變換的截尾操作將不會帶入誤差,因此,Δx(8)=Δx=(1+1.5+1.52+…+1.56)≈32.2Δx。在小波分解的后續處理中,往往要先進行取整運算。因此,若Δx(8)<1,即Δx<32.2-1<2-6,n≥5,截尾帶來的累計誤差將不會影響后續處理的精度。
3.2.3 數據動態范圍與精度的確定
經過上述分析,若要同時保證動態范圍和精度,則中間數據需保留13+5=18位。通常數據長度選取16、24或32等。顯然,選取后兩種數據長度可以滿足要求,但是要消耗更多的硬件資源。而選取16位似乎又不能滿足動態范圍和精度的要求。
上述動態范圍和精度分析都是考慮到最壞的情況。而實際情況并非如此,最壞情況出現概率微乎其微。表1是幾幅標準圖像的動態范圍統計。
?
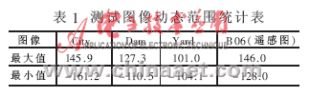
可見,實際圖像的處理中數據的動態范圍并不大。9位(±256)已經可以滿足絕大多數應用,而小數部分要求n≥5,各保留1 位的余量(即10位整數、6位小數),16位數據長度正好可以滿足需要。
3.3? 設計、實現與測試
基于Virtex E 系列的XCV600E-7芯片,設計了一套512×512象素圖像的四級小波分解系統。XCV600E器件內部共有6912個Slices(邏輯功能塊)、13824個Registers(寄存器)、13824個4 Input LUT(四輸入查找表)和72個Block RAM,適用于較復雜的處理器設計。芯片的接口速率達到200MHz(Xilinx數據手冊提供的數據),能提供足夠的輸入輸出帶寬。經過設計、仿真與實現,完成小波分解的資源消耗和性能基本達到了預想的效果。
用VHDL語言描述的設計版本,共消耗了
Slices: 6344個(91%), Register: 4970個(35%),
????4 Input LUT: 10311個(74%), Block RAM: 40個(55%)。
用Xilinx公司例化元件的設計版本,共消耗了
Slices: 3524個(51%), Register: 4668個(34%),
4 Input LUT: 6345個(46%), Block RAM:40個(55%)。
從資源的消耗情況來看,該芯片完全可以進行1024×1024大小圖像的分解以及進行第5級分解。
通過對系統進行的實際測試可知,系統的數據處理速率高達120MHz;根據仿真的波形可知,最大的數據不穩定時間≤2.5ns。而系統正常穩定工作時要求數據的不穩定時間小于工作周期的一半,因此系統的工作頻率完全可以提升到200MHz甚至更高。在實際的系統中,此項性能主要受限于FPGA的接口速率,若選用更高檔的芯片,將達到更好的效果。
經過FPGA的分解和重構,得到的結果如圖6所示。經測試,重構圖像在進行取整運算后,重構圖像與原始圖像完全無失真,即峰值信噪比PSNR為無窮大。可見,由于設計中正確地選取了數據的動態范圍和數據精度,在節省了中間存儲器空間的同時使分解和重構運算的截尾誤差未給圖像的恢復帶來損失。
?

?
3.4 改進后的FPGA實現方法的顯著優勢
為了對改進后的方法進行性能比較,采用普通的FPGA實現方法設計了一套512×512圖像的4級小波分解系統。經過測試,得到表2所示數據。
?

?
由表2的前兩項數據可見,需要設計8個相同的濾波器,而普通方法只需設計一個16位的濾波器和幾個控制模塊,因此前者比后者消耗了更多的FPGA資源;改進方法將中間數據在芯片內作緩沖,消耗了40個Block RAM塊。改進方法在資源的消耗上雖然不及前者,但是在大規模FPGA芯片成為設計主流載體的今天,資源的消耗問題已經不象以往那樣至關重要。
目前大家最關心的問題,也是改進后方法的主要優勢,就是對圖像的處理效率高、節省了外部的存儲器資源。在圖像數據連續進入系統的情況下,普通的方法為了解決中間數據在外部RAM中的存儲問題,只有設計多條(3條以上)單獨的數據通道和多塊獨立的RAM來分別完成數據的緩沖、中間結果存儲、結果緩存。由于圖像處理的中間結果都要緩沖到外部存儲器并要多次通過分解模塊進行處理,若要實時地完成數據處理,就要求器件的工作頻率以及與存儲器的接口速率能夠達到圖像數據輸入速率2.5倍左右。而改進后的方法,在處理圖像數據時將中間結果存儲于FPGA內部,而且中間數據依次通過各級分解模塊,FPGA的工作頻率只要和圖像數據的輸入速率一致即可以滿足要求。當圖像的輸入速率達到100MHz量級時,普通方法要求FPGA的工作頻率和存儲器接口速率都要達到250MHz,這對大多數FPGA和RAM都是難以突破的瓶頸。因此,在器件相同的情況下,改進后的系統可達到普通系統處理速度的2.5倍。
由此可見,普通方法適合于圖像數據率比較低、對系統的成本要求比較嚴格的情況,改進方法則適合應用于對性能要求很高而對成本要求不高的情況。
本文提出的基于FPGA的高速圖像小波分解實現方法比傳統的實現方法在處理速度方面有了很大的提高。特別是在對連續圖像進行處理時,可以不進行圖像數據的分割和緩沖而進行連續的處理,節省了分塊緩沖的時間和存儲空間。在圖像重構系統中采用同樣的結構即可連續地恢復出原始圖像。在實際的應用中,小波分解模塊并不是孤立存在的,經過小波分解后的數據還要進行數據壓縮、數據融合、邊緣檢測等處理。根據后續模塊實現方案的具體情況,在FPGA中設計與后續處理模塊匹配的數據通道,小波分解模塊即可方便地與相應的圖像處理系統進行級聯。因此,本文提出的高速小波分解模塊可以廣泛應用于基于小波分解的各種圖像處理算法的實時處理系統,使小波分解部分不再成為整個圖像處理系統的瓶頸。
?
參考文獻
1 Thomas W. Fry. Hyperspectral Image Compression on Reconfigurable Platform. Washington University,2000
2 Jonathan B. Ballagh. An FPGA Run-time Reconfigurable 2-D Discrete Wavelet Transform Core. Virginia, June 2001
3 K. Chapman.Fast Integer Multipliers Fit in FPGAs. Electronic Design News, May 12, 1994
4 Spaniol. Computer Arithmetic: Logic and Design,John Wiley & Sons,1981
5 Xilinx. Xilinx VirtexE Data Book.San Jose CA,2000
6 李在銘.數字圖像處理、壓縮與識別技術.成都:電子科技大學出版社,2000
7 Castleman,K. R著,朱志剛譯.數字圖像處理.北京:電子工業出版社,1998