
1引言
當今,各種信息系統的數據量越來越大,如何更快、更多、更好地傳輸與存儲數據成為數據信息處理的首要問題,而數據壓縮技術則是解決這一問題的重要方法。事實上,從壓縮軟件WINRAR到熟知的MP3,數據壓縮技術早已應用于各個領域。
2 數據壓縮技術概述
本質上壓縮數據是因為數據自身具有冗余性。數據壓縮是利用各種算法將數據冗余壓縮到最小,并盡可能地減少失真,從而提高傳輸效率和節約存儲空間。
數據壓縮技術一般分為有損壓縮和無損壓縮。無損壓縮是指重構壓縮數據(還原,解壓縮),而重構數據與原來數據完全相同。該方法用于那些要求重構信號與原始信號完全一致的場合,如文本數據、程序和特殊應用場合的圖像數據(如指紋圖像、醫學圖像等)的壓縮。這類算法壓縮率較低,一般為1/2~1/5。典型的無損壓縮算法有:Shanno-Fano編碼、Huffman(哈夫曼)編碼、算術編碼、游程編碼、LZW編碼等。而有損壓縮是重構使用壓縮后的數據,其重構數據與原來數據有所不同,但不影響原始資料表達信息,而壓縮率則要大得多。有損壓縮廣泛應用于語音、圖像和視頻的數據壓縮。常用的有損壓縮算法有PCM(脈沖編碼調制)、預測編碼、變換編碼(離散余弦變換、小波變換等)、插值和外推(空域亞采樣、時域亞采樣、自適應)等。新一代的數據壓縮算法大多采用有損壓縮,例如矢量量化、子帶編碼、基于模型的壓縮、分形壓縮和小波壓縮等。
3 常用數據無損壓縮算法
3.1 游程編碼
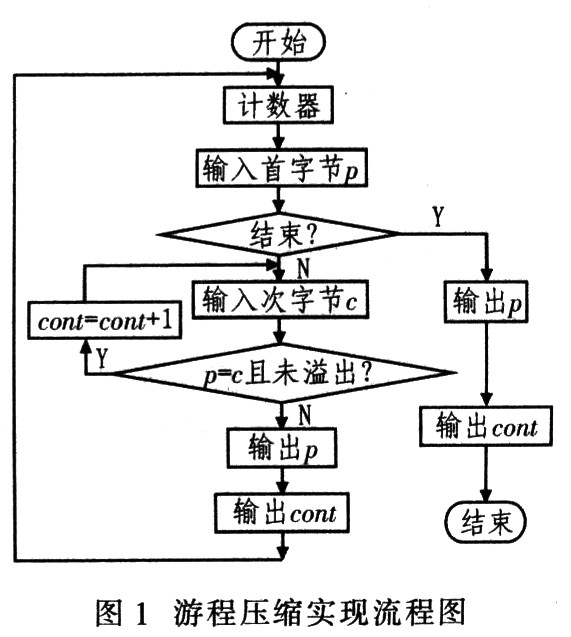
這種數據壓縮思想:如果數據項d在輸入流中連續出現n次,則以單個字符對nd來替換連續出現n次的數據項,這n個連續出現的數據項叫游程n,這種數據壓縮方法稱游程編碼(RLE),其實現流程如圖1所示。RLE算法具有實現簡單,壓縮還原速度快等優點,只需掃描一次原始數據即可完成數據壓縮。其缺點是呆板,適應性差,不同的文件格式的壓縮率波動大,平均壓縮率低。實踐表明,RLE能夠壓縮復雜度不高的原始點陣圖像。
3.2 基于字典編碼技術的LZW算法
LZW算法是LZ78的流行變形,由Terrv Welch在1984年開發。LZW算法首先將字母表中的所有字符初始化到字典,常用8位字符,在輸入任何數據前優先占用字典的前256項(0~255)。LZW編碼的原理:編碼器逐個輸入字符并累積一個字符串I。每輸入一個字符則串接在I后面,然后在字典中查找I;只要找到I,該過程繼續執行搜索。直到在某一點,添加下一個字符x導致搜索失敗,這意味著字符串I在字典中,而Ix(字符x串接在I后)卻不在。此時編碼器輸出指向字符串,的字典指針;并在下一個可用的字典詞條中存儲字符串Ix;把字符串I預置為x。其壓縮流程如圖2所示。
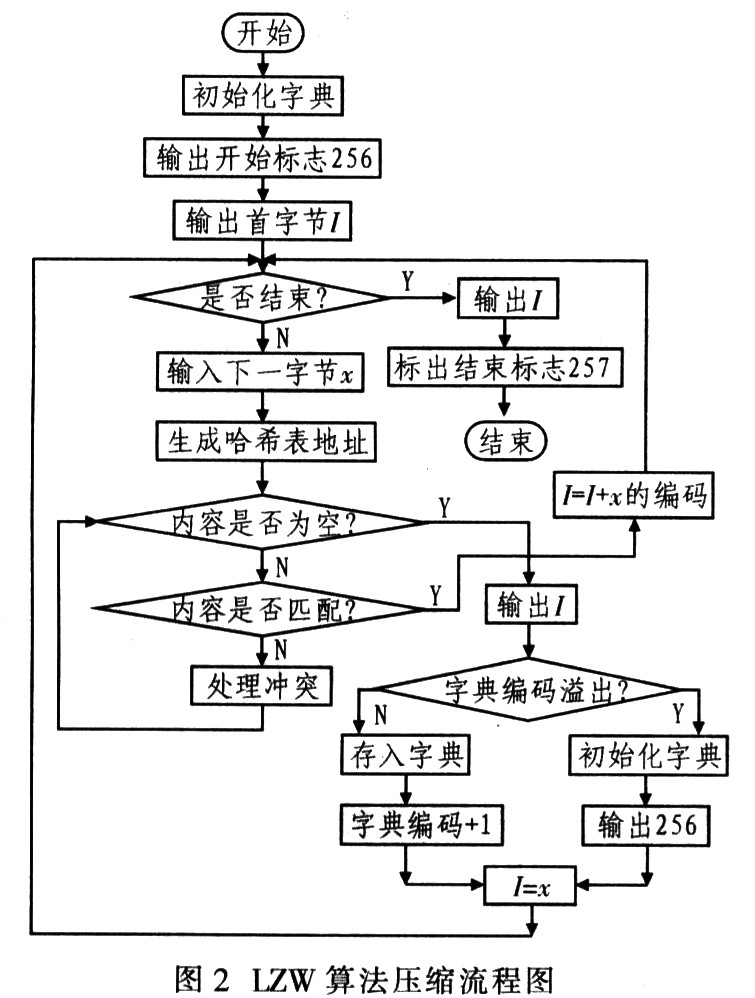
因為字典的前256項被占用,因此字典指針必須高于8位。由于LZW算法的字典中的字符串每次僅增加一個字符。因此,要獲得長字符串則需較長時間,這樣才能較好地壓縮.IZW編碼能夠適應輸入數據。
LZW算法與其他算法相比具有自適應的特點,即可以根據壓縮內容不同來建立不同字典,以減少冗余度,提高壓縮比;并且解壓時這個字典無需與壓縮代碼同時傳送,而是在解壓過程中逐步建立與壓縮時完全相同的字典,從而完整、準確地恢復被壓縮內容。因此,LZW算法是一種解碼速度與壓縮性能較好的壓縮算法。
實現LZW算法需要考慮以下幾點:
(1)字典建立(數據結構與字典大小) LZW字典的數據結構是一棵多叉樹。字典越大,代替的子串越多。但應用中字典容量則受一定限制,要權衡利弊選擇合適的字典。
(2)字典維護與更新字典指針由哈希函數生成。正確選擇哈希函數非常重要,這將影響執行效率。正確的哈希函數所產生的重復值極少,這樣檢索字符串所需比較次數也較少,從而可有效提高代碼的執行效率。
當字典滿時,字典的維護和更新對壓縮率也是至關重要的。可重新從初始狀態建立字典;也可監測壓縮率,當壓縮率變壞時全部或部分清除字典。
(3)壓縮數據代碼長度壓縮時,輸入數據一般是8位。但壓縮后的輸出是轉化的字符串代碼,其中0~255為8位碼,256為9位碼,25l~512為10位碼,l 024為11位碼。解壓則相反,需要位操作。因此,輸出可以從9位碼開始,隨著字典內容的增加,碼字也逐漸增加。這樣可提高執行效率,但在譯碼時需考慮不等長碼的識別,可通過設置標志位來解決。
3.3 基于哈夫曼編碼原理的壓縮算法
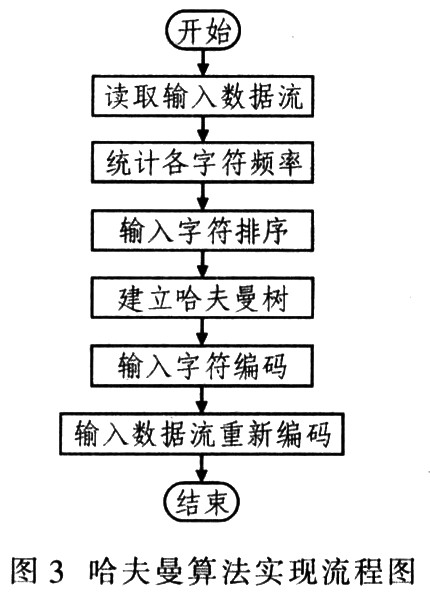
哈夫曼算法的過程為:統計原始數據中各字符出現的頻率;所有字符按頻率降序排列;建立哈夫曼樹:將哈夫曼樹存入結果數據;重新編碼原始數據到結果數據。哈夫曼算法實現流程如圖3所示。
哈夫曼算法的實質是針對統計結果對字符本身重新編碼,而不是對重復字符或重復子串編碼。實用中.符號的出現頻率不能預知,需要統計和編碼兩次處理,所以速度較慢,無法實用。而自適應(或動態)哈夫曼算法取消了統計,可在壓縮數據時動態調整哈夫曼樹,這樣可提高速度。因此,哈夫曼編碼效率高,運算速度快,實現方式靈活。
采用哈夫曼編碼時需注意的問題:
(1)哈夫曼碼無錯誤保護功能,譯碼時,碼串若無錯就能正確譯碼;若碼串有錯應考慮增加編碼,提高可靠性。
(2)哈夫曼碼是可變長度碼,因此很難隨意查找或調用壓縮文件中間的內容,然后再譯碼,這就需要在存儲代碼之前加以考慮。
(3)哈夫曼樹的實現和更新方法對設計非常關鍵。
3.4 基于算術編碼的壓縮算法
算術編碼壓縮也是一種根據字符出現概率重新編碼的壓縮方案。該思想和哈夫曼編碼有些相似,但哈夫曼編碼的每個字符需用整數個位表示。而算術編碼方法則無這一限制,它是將輸入流視為整體進行編碼。雖然算術編碼壓縮率高.但運算復雜,速度慢。
4 結語
游程編碼和LZW編碼屬于基于字典模型的壓縮算法,而哈夫曼編碼和算術編碼屬于基于統計模型的壓縮算法,前者與原始數據的排列次序有關而與其出現頻率無關,后者則正好相反。這兩類壓縮方法算法思想各有所長,相互補充。許多壓縮軟件結合了這兩類算法。例如WINRAR就采用了字典編碼和哈夫曼編碼算法。這幾種數據無損壓縮算法應用廣泛,設計人員可以根據具體應用中的數據流特點來改進算法從而開發適用的軟硬件壓縮器。