
摘 要: 研究了MIMO-GMC" title="MIMO-GMC">MIMO-GMC系統(tǒng)中高效信道估計" title="信道估計">信道估計及其FPGA實現(xiàn)技術(shù)。通過大量研究和設(shè)計,得到一種既能保證性能和速度,又適合硬件實現(xiàn)的信道估計算法。采用Xilinx公司的FPGA芯片Vertex-II Pro 100和適量的并行流水方案,設(shè)計出高速可行的MIMO信道估計器,單片實現(xiàn)3個載波的信道估計。經(jīng)海量測試,驗證了硬件的正確性和魯棒性。
關(guān)鍵詞: MIMO-GMC DCT變換? 單點" title="單點">單點濾波? FPGA
?
為適應未來發(fā)展的需要,提高系統(tǒng)的頻譜利用率,在后三代(B3G)或稱第四代(4G)移動通信的MIMO-GMC系統(tǒng)中,采用了多天線發(fā)送和多天線接收的空中接口機制。為了可靠有效地支持高速傳輸,MIMO-GMC系統(tǒng)仍需要很高的帶寬。寬帶傳輸加重了頻率選擇性衰落,造成嚴重的多徑干擾;而終端的高速移動性導致的多普勒頻移,加重了時間選擇性衰落。因而,在這種雙選擇性衰落的信道條件下,迫切需要采用一種高速率、高性能的信道估計技術(shù)。
為了實現(xiàn)相干接收,需要估計信道的沖激響應系數(shù)和噪聲方差。為了能夠及時準確地估計出信道參數(shù),設(shè)計了一種基于循環(huán)正交碼的雙循環(huán)時隙" title="時隙">時隙結(jié)構(gòu),采用循環(huán)正交序列不同相位的循環(huán)移位序列作為不同發(fā)送天線的導頻" title="導頻">導頻序列。在接收端,利用循環(huán)正交序列的特性,以低實現(xiàn)復雜度獲得最小二乘(LS)意義上最優(yōu)的信道估計,利用時域相關(guān)性獲得導頻段更為精確的最小均方誤差(MMSE)意義上最優(yōu)的信道估計,進一步采用插值可獲得數(shù)據(jù)段信道參數(shù)的估計。
1 信道估計原理[1]
發(fā)送信號的時隙結(jié)構(gòu)如圖1所示。定義一個時隙有K個子時隙,每個子時隙都由保護段(G)、導頻段(P)和數(shù)據(jù)段(D)組成,在每個時隙的最后一個子時隙后追加一個保護段和一個導頻段來構(gòu)成該時隙。
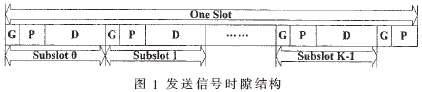
在MIMO_GMC系統(tǒng)中,發(fā)送天線個數(shù)為NT,接收天線的個數(shù)為NR。假設(shè)信道沖激響應序列的長度為P,即假設(shè)有P徑,則每個接收通道待估計的信道參數(shù)個數(shù)為NTP,相應的導頻序列長度應該滿足LP≥NTP。
信道估計原理如圖2所示。首先用接收的導頻段數(shù)據(jù)與存儲原始發(fā)送導頻的共軛進行矩陣乘法運算,得到LS意義上的信道沖激響應系數(shù)。將得到的LS信道系數(shù)送到噪聲方差估計模塊進行能量統(tǒng)計,并結(jié)合接收導頻數(shù)據(jù)的能量統(tǒng)計值得到噪聲方差的估計;同時將每個時隙的LS信道參數(shù)變換到DCT域進行單點濾波。最后在IDCT變換的同時進行插值,得到數(shù)據(jù)段的MMSE信道沖激響應輸出。
2 信道估計的FPGA實現(xiàn)
在B3G的MIMO-GMC系統(tǒng)上行鏈路中采用4發(fā)8收的空中接口方案,接收符號速率為每載波1.28MHz,總共有12個載波傳送數(shù)據(jù),系統(tǒng)傳輸能力達到100Mbps。對于時隙結(jié)構(gòu),每個時隙包含5個導頻段,導頻長度32,保護段長度8,數(shù)據(jù)段長度216。采用高速可靠的信道估計器實現(xiàn),假設(shè)總共有6徑,使用92.16MHz的工作時鐘來實現(xiàn),則一個時隙總共有77 184個時鐘周期。
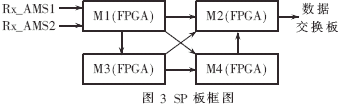
在MIMO-GMC硬件實現(xiàn)中,接收機總共使用了4塊如圖3所示結(jié)構(gòu)的信號處理(SP)板,M1同時接收來自兩塊Rx-AMS(接收預處理)板各4根天線3個載波的同步接收信號。按照載波將8根天線的接收信號分配到3個相同的信道估計和空時合并模塊進行處理;3個載波的合并結(jié)果通過接口輸出到M2~M4分別進行迭代檢測譯碼;最后將譯碼結(jié)果匯聚到M2板輸出到數(shù)據(jù)交換板。其中M1~M4均采用Xilinx公司Vertex II Pro 100芯片[2]。
信道估計部分按照功能主要劃分為三大模塊,分別是最小二乘信道估計模塊(LS)、噪聲方差估計模塊(Var)和DCT域插值濾波模塊(DCTFilter),如圖4所示,其中DCTFilter模塊包含DCT變換、單點濾波和IDCT插值變換。圖中Source模塊接收分別來自兩塊AMS板的同步數(shù)據(jù),將其合并,并按照載波分配到三個相同的信道估計模塊進行處理。

2.1 Source模塊FPGA實現(xiàn)
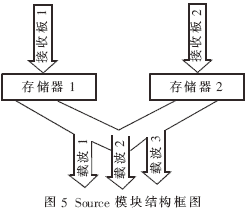
Source模塊主要由兩塊18KB雙端口BlockRAM組成,如圖5所示。將兩塊RAM當作FIFO使用,兩個端口分別為輸入和輸出,分別接收存儲來自兩塊Rx_AMS板各4根天線的同步數(shù)據(jù)。兩塊RAM每存滿1個符號(3個載波各4根天線共12個復數(shù)數(shù)據(jù)),就將3個載波的數(shù)據(jù)按照8根天線的順序分別輸出到3個寄存器,同步輸出給3個信道估計模塊。
這里考慮到來自兩塊Rx_AMS板的數(shù)據(jù)不可能完全同步到達,而且存在數(shù)據(jù)到達先后的問題,所以采用兩塊FIFO來實現(xiàn)。這樣兩路數(shù)據(jù)同一符號之間的輸入時差即使達到3 000個時鐘周期,亦能正常工作,大大增強了系統(tǒng)魯棒性。
?
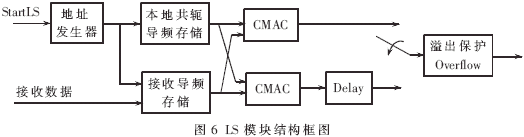
2.2 LS模塊FPGA實現(xiàn)
LS模塊結(jié)構(gòu)框圖如圖6所示,將存儲的發(fā)送導頻的共軛與接收到的導頻信號進行矩陣乘法運算,得到信道沖擊響應系數(shù)輸出。
由于本地共軛導頻是由原導頻循環(huán)右移產(chǎn)生各發(fā)送天線的導頻段,所以這里只要存儲第一個原始導頻的32個數(shù)據(jù)。在讀取時只要對讀取地址加適當?shù)钠频刂肪涂梢宰x到發(fā)送到相應天線的導頻數(shù)據(jù)。這里采用分布式RAM來存儲,將初值直接置入,設(shè)置為只讀模式。
對于接收導頻存儲RAM,由于一個導頻段有256個數(shù)據(jù),為了保證接收存儲和輸出運算不沖突,這里采用深度為512B的雙端口RAM構(gòu)造乒乓結(jié)構(gòu),用最高位地址線進行兩塊存儲區(qū)的區(qū)分,RAM兩端口,一個只寫另一個只讀。
雖然這里的接收存儲RAM采用了乒乓結(jié)構(gòu)來實現(xiàn),但每個時隙最后一個導頻段與下一時隙第一個導頻段是連續(xù)輸入的,而該時隙的后續(xù)估計工作需要在下一時隙第一個導頻段開始LS估計前完成,否則后續(xù)的估計模塊均需要乒乓結(jié)構(gòu)才能保證兩個時隙的估計不沖突,這樣將耗費大量資源。為了解決這一沖突,首先設(shè)置了一個LS估計開始信號(Start LS)來控制每個導頻段LS估計開始的時間,對于每個時隙的第一個導頻段,總等到前一個時隙信道估計完全結(jié)束以后才能開始,以保證其輸出對前一個時隙的估計不產(chǎn)生影響;對于其余導頻段,接收完成即開始LS估計,以盡量減少輸出時延。但僅僅進行以上措施依然不能解決沖突問題,所以還需要對各個估計模塊進行并行處理,以保證工作速率,從而保證前一個時隙的信道估計完全輸出以后,依然有足夠的時間處理下一個時隙的接收導頻,使得RAM中的數(shù)據(jù)在處理完成之前不被后續(xù)到來的導頻數(shù)據(jù)刷新,即在下一個時隙的第一個子時隙內(nèi)必須完成當前時隙的信道估計的全部工作。
從圖6可以看出,這里采用了兩路復數(shù)乘法累加器來實現(xiàn)LS估計以提高速度。但這里對RAM的讀寫提出了特殊要求,兩塊RAM需要同時輸出兩個不同的信號。考慮到對于不同的接收天線,其發(fā)送導頻順序是一樣的,這樣如果當前處理的僅僅是不同接收天線同一位置同一徑的數(shù)據(jù),即所需讀取的本地導頻也一樣,則本地導頻輸出僅需一個。對于接收導頻存儲RAM,利用雙端口RAM的特性[2],將輸出端口寬度設(shè)置為輸入端口寬度的兩倍,將接收導頻的存儲地址的低地址設(shè)置為接收天線,這樣每次輸出均能同時輸出相鄰兩根接收天線的導頻數(shù)據(jù),保證了并行處理的數(shù)據(jù)源,最終將兩路并行輸出數(shù)據(jù)并串轉(zhuǎn)換,串行輸出。由于導頻長度為32,所以兩路數(shù)據(jù)每32個時鐘分別輸出1個信道參數(shù)。這樣兩路串行以后每32個時鐘周期連續(xù)輸出2個信道參數(shù)。
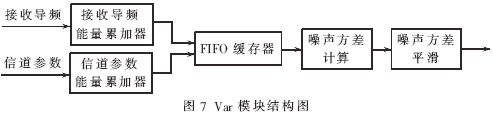
2.3 Var模塊FPGA實現(xiàn)
Var模塊結(jié)構(gòu)框圖如圖7所示。該模塊同時接收系統(tǒng)輸入的導頻信號和LS模塊輸出的信道參數(shù),將其分別進行能量累加,通過一個FIFO同步輸出到噪聲方差計算模塊,得到當前時隙的噪聲方差,與存儲的前一時隙的噪聲方差進行平滑處理得到當前噪聲方差輸出。
?
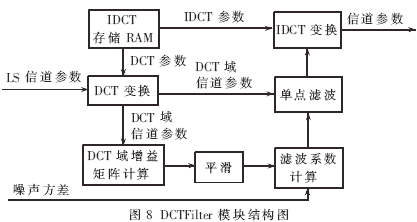
2.4 DCTFilter模塊FPGA實現(xiàn)
DCTFilter模塊結(jié)構(gòu)框圖如圖8所示。該模塊接收初次信道估計參數(shù)對其進行DCT變換,存儲結(jié)果的同時對其按照塊和徑進行信道增益矩陣統(tǒng)計。一個時隙的信道參數(shù)全部輸入完成以后,對得到的信道增益矩陣與存儲的前一時隙的信道增益矩陣進行平滑處理得到當前時隙的信道增益矩陣,計算出單點濾波矩陣,接著用其對信道參數(shù)進行單點濾波,最后做IDCT插值變換輸出,得到MMSE信道參數(shù)輸出。
從圖8可以看出,這里僅用一塊RAM存儲一個17×5的IDCT陣,而沒有存儲DCT陣,這是由于5×5的DCT矩陣是IDCT矩陣模4余1行全部元素的轉(zhuǎn)秩。
DCT子模塊接收來自LS模塊的信道參數(shù),按照公式:

計算出DCT域的信道參數(shù),其中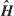 5x192代表輸入的信道參數(shù),其5行分別代表5個導頻段的信道參數(shù),是按照時間順序輸入的。如果按照通常設(shè)計方案,需要存儲輸入的信道參數(shù),等到一個時隙的數(shù)據(jù)完全存儲以后才開始DCT變換,并用另外一個存儲單元來存儲DCT域的信道參數(shù)。但這樣的設(shè)計有兩個缺點:(1)需要大量的存儲空間來存儲信道參數(shù),存儲壓力很大;(2)大量時間系統(tǒng)處于等待狀態(tài),對于時延要求如此苛刻的系統(tǒng),這更加重了后續(xù)模塊的處理壓力。這里將公式(1)變形為:
5x192代表輸入的信道參數(shù),其5行分別代表5個導頻段的信道參數(shù),是按照時間順序輸入的。如果按照通常設(shè)計方案,需要存儲輸入的信道參數(shù),等到一個時隙的數(shù)據(jù)完全存儲以后才開始DCT變換,并用另外一個存儲單元來存儲DCT域的信道參數(shù)。但這樣的設(shè)計有兩個缺點:(1)需要大量的存儲空間來存儲信道參數(shù),存儲壓力很大;(2)大量時間系統(tǒng)處于等待狀態(tài),對于時延要求如此苛刻的系統(tǒng),這更加重了后續(xù)模塊的處理壓力。這里將公式(1)變形為:
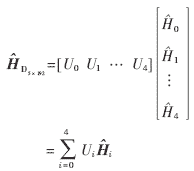
其中Ui是DCT陣的列,而 i對應的則是第i個導頻段信道參數(shù)。從變形以后的公式可以看出,輸入信道參數(shù)無需存儲,每輸入一個數(shù)據(jù),與相應DCT系數(shù)相乘,與存儲的DCT信道參數(shù)累加再存儲,便可以得到DCT域的信道參數(shù);另一方面,LS信道參數(shù)的輸入完成以后只需經(jīng)過幾個時鐘周期,DCT域信道參數(shù)計算就可完成了,大大壓縮了系統(tǒng)延遲。
i對應的則是第i個導頻段信道參數(shù)。從變形以后的公式可以看出,輸入信道參數(shù)無需存儲,每輸入一個數(shù)據(jù),與相應DCT系數(shù)相乘,與存儲的DCT信道參數(shù)累加再存儲,便可以得到DCT域的信道參數(shù);另一方面,LS信道參數(shù)的輸入完成以后只需經(jīng)過幾個時鐘周期,DCT域信道參數(shù)計算就可完成了,大大壓縮了系統(tǒng)延遲。
每計算出一個DCT域的信道參數(shù)以后,除了送到存儲單元以外還直接送到信道增益矩陣(PG)統(tǒng)計模塊,按照塊和徑進行統(tǒng)計。這里每得到一個DCT域信道參數(shù)便進行一次統(tǒng)計,所以對系統(tǒng)產(chǎn)生極少的系統(tǒng)延時。其輸出結(jié)果與存儲的上一個時隙的增益矩陣進行平滑,得到當前時隙的增益矩陣存儲;同時輸出到濾波矩陣計算模塊計算出濾波系數(shù)。
在所有濾波系數(shù)計算完成以后,就開始對DCT域的信道系數(shù)進行單點濾波,接著進行IDCT變換輸出。這里是個計算密集型單元,數(shù)據(jù)輸出速度完全受計算速度控制。乘法器并行程度越高,輸出時延越小,但同時消耗的資源也越多,這就需要找一個合適的折衷方案在滿足時延的需求下盡量減少資源開銷。對于單點濾波,每一個DCT域的信道參數(shù)均要進行單點濾波,即每讀取一個存儲的DCT域的信道參數(shù)都要進行一次乘法運算;對于IDCT變換,每輸出一個數(shù)據(jù)需要進行5次乘法運算,總共要輸出3 264個數(shù)據(jù),即進行16 320次乘法。如果不復用則總共需要16 320個時鐘周期,而一個子時隙只有18 432個時鐘周期,加上其他模塊的處理延遲,就不能滿足系統(tǒng)時延要求了,因此,這里采用兩路并行處理。
在單點濾波和IDCT變換處理過程中涉及3個RAM的存取:濾波矩陣存儲RAM、DCT域信道參數(shù)存儲RAM和IDCT系數(shù)存儲RAM。這里采用與DCT變換類似的方法來解決從不同的RAM中同時讀取兩路數(shù)據(jù)的方法,這是因為對于相同發(fā)送天線、相同導頻段、相同徑的DCT域信道參數(shù)其濾波系數(shù)和IDCT系數(shù)都是相同的,這里不再重述。
3 信道估計器硬件測試
信道估計器的硬件測試主要由單模塊測試和系統(tǒng)測試兩部分組成。
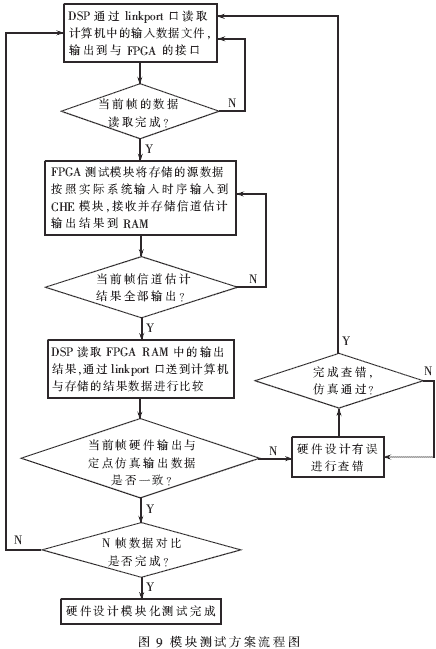
模塊測試方案如圖9所示,利用DSP的linkport口與計算機之間的通信能力,對FPGA進行海量數(shù)據(jù)測試,通過大量測試保證硬件設(shè)計的魯棒性。
系統(tǒng)測試主要是將信道估計器放入MIMO-GMC系統(tǒng)中進行測試,保證系統(tǒng)正常運行,達到仿真預計的性能。
本文重點研究了MIMO-GMC系統(tǒng)中的信道估計的硬件實現(xiàn),設(shè)計出一套適合硬件實現(xiàn)的MIMO信道估計算法,完成FPGA設(shè)計,并通過大量模塊測試和系統(tǒng)測試,包括大量的現(xiàn)場測試,支持12個載波100Mbps無誤碼的無線傳輸速率,得到了一個高速率、高魯棒、高性能的信道估計器。
參考文獻
[1] GAO Xi Qi, JIANG Bin, YOU Xiao Hu,et al. Efficient channel estimation for MIMO single-carrier block transmi-ssion with dual cyclic timeslot structure. Submitted to IEEE Trans. Commun.
[2] Virtex-II Pro Platform FPGA Handbook. UG012(v1.0).Xilinx January 31, 2002.
[3] YOU Xiao Hu,CHEN Guo An,CHEN Ming,et al.Toward beyond 3G:the FuTURE project of China[J].IEEE Comm-unications Magazine, 2005,43(1):70-75.
[4] GAO Xi Qi. MIMO-GMC Wireless Transmission Technique [R]. National 863 FuTURE Project Research Report,Southeast University, 2004.
[5] PETER H, FICDRIK T. Channel estimation with superim-posed pilot sequence. Advanced Signal Processing for Comm-unications. Global Telecommunications Conference-Globecom’99.
[6] 高西奇,尤肖虎,江彬等.面向后三代移動通信的MIMO-GMC無線傳輸技術(shù). 電子學報,2004,(12A)